MongoDB 기본 특징
몽고디비(MongoDB)가 가지는 기본적인 특징에 대해서 알아봅시다…
데이터 모델
- DB -Database는 Collection들의 물리적인 컨테이너. 각 Database는 파일시스템에 여러파일들로 저장됩니다.
- Collection (Table) - MongoDB Document의 그룹
- Document (Record)
- Key : Value (Field)
(참고)
- Mongodb : db > collection > document > key:value
- Cassandra : Key-space > Table > Row > Column name : Column value
- RDBMS : DB > Table > row > column
- elasticsearch : index > type> document > key : value
C++기반
Schemaless (Schema-fre)
- 스키마란?
- 데이터베이스를 구성하는 개체(Entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작 시에 데이터 값들이 갖는 제약조건 등에 관해 전반적으로 정의하는 것이다.
- Schema가 존재한다는 것은 그 구조가 미리 정의되어 있어야 한다는 의미. 이는 데이터의 급격한 변화에 대응하기 힘듬.
- MongoDB 는 이러한 스키마가 사전에 정의되지 않아도 된다.
- 데이터베이스에 저장된 Document는 각기 다른, 다양한 필드를 가질 수 있다.
- 각 필드는 서로 다른 데이터타입을 가질 수 있다.
- It actually mean dynamically typed schema.
- Unstructured data 를 쉽게 저장할 수 있음
Document Oriented (Uses BSON format)
- mongodb document database(official)
- 하나의 row에 하나의 Document를 저장한다.
- BSON : It adds support for data types like ‘'’Date’’’ and ‘'’binary’’’ that aren’t supported in JSON
- Unstructured data 와 복잡한 데이터구조를 쉽게 저장할 수 있음.
- Join 대신 Embedded document를 활용 가능
- Dynamic schema은 다형성(polymorphism)을 가능케한다.
Deep query-ability
- 강력한 쿼리 기능을 가지는 것이 mongodb 의 특징이다.
- mongodb-archtecture (official)
- document-based query language 로 파워풀한 query를 지원함
- javascript expressions 으로 이해하기 쉽다.
- 다양한 쿼리기능
- Key-value queries : return results based on any field in the document, often the primary key.
- Range queries : return results based on values defined as inequalities (e.g. greater than, less than or equal to, between).
- Geospatial queries: return results based on proximity criteria, intersection and inclusion as specified by a point, line, circle or polygon.
- Search queries: return results in relevance order and in faceted groups, based on text arguments using Boolean operators (e.g.,
AND,OR,NOT), and through bucketing, grouping and counting of query results. With support for collations, data comparison and sorting order can be defined for over 100 different languages and locales. - (built in) Aggregation Framework queries : return aggregations and transformations of values returned by the query (e.g., count, min, max, average, similar to a SQL GROUP BY statement).
- JOINs and graph traversals : Through the $lookup stage of the aggregation pipeline, documents from separate collections can be combined through a left outer JOIN operation. $graphLookup brings native graph processing within MongoDB, enabling efficient traversals across trees, graphs and hierarchical data to uncover patterns and surface previously unidentified connections.
- MapReduce queries : execute complex data processing that is expressed in JavaScript and executed across data in the database.
- (참고) - mongodb map reduce
- (참고) - MapReduce란?
Supports Aggregation
- GROUP BY절을 이용하여 그룹 당 하나의 결과로 그룹화 할 수 있다.
- HAVING절을 사용하여 집계함수(Aggregation)를 이용한 조건 비교를 할 수 있다.
- MIN, MAX 함수는 모든 자료형에 사용 할 수 있다.
- 일반적으로 가장 많이 사용하는 집계함수에는AVG(평균), COUNT(개수), MAX(최대값), MIN(최소값), SUM(합계) 등이 있다.
Indexing (Any field in MongoDB can be indexed)
- RDBMS인 MySQL에서 지원하는 대부분의 인덱스를 지원
- 이처럼 강력한 인덱스 기능 덕분에 거의 모든 쿼리들을 빠르게 처리할 수 있다.
- 다른 NoSQL에서 찾아보기 힘든 장점이다.
- Index는 메모리에 저장되기 때문에 메모리 크기에 영향을 많이 받는다.
- Adhoc 쿼리 지원 : (미리 정의되지 않은 쿼리. 동적으로 변하는 쿼리 )
- Single Field Indexes : 가장 기본적인 인덱스 타입
- Compound Indexes : RDBMS에서 많이 쓰이는 복합 인덱스
- Multikey Indexes : Array에 매칭되는 값이 하나라도 있으면 인덱스에 추가하는 멀티키 인덱스
- Geospatial Indexes and Queries : 위치 기반 인덱스와 쿼리
- Text Indexes : String 컨텐츠에도 인덱싱이 가능
- Hashed Index : BTree 인덱스가 아닌 Hash 타입의 인덱스도 사용 가능
- “MongoDB를 쓰면서 알게 된 것들”-한글블로그
Fixed Size Collection
- Capped collections 라고도 불린다.
- Collection의 사이즈를 고정할 수 있으며 , 큐 처럼 동작함.
Supports Multiple Storage Engines
- mongodb multiple storage engine
- 스토리지 엔진: 데이터가 어떤식으로 저장되는지 매니징 하는
- WiredTiger Storage Engine (최신 버전의 Default)
- MMAPv1 Storage Engine (과거 버전의 Default)
- Third party storage engine 을 적용할 수 있는 API를 제공.
Fast In-Place Updates
- update-in-place(official doc)
- 고성능의 atomic operation을 지원
- 이 특징이 무슨 의미인지 좀 더 조사해보자. 확실히!
GridFS
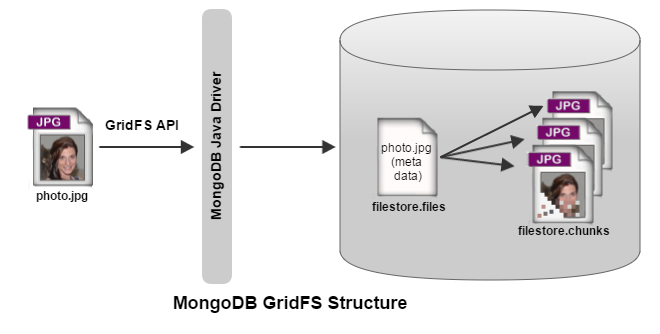
- 대용량 파일을 저장하기 위한 Grid File System.
- MongoDB 는 document 하나의 크기가 최대 16MB 로 제한된다.
- 그 이상의 파일을 저장하기 위해서 Large File을 작은 파트로 분할해서 분리된 Documents 로 저장하는 MongoDB driver 를 제공한다.
- 해당 컨텐츠를 요구하면 분리된 작은 Chunks를 자동으로 모아서 오리지널 파일을 반환한다.
- 별도 스토리지 엔진을 통해 파일을 저장가능
- image/video PDFs, PPT slides or Excel spreadsheets 와 같은 컨텐츠의 저장소로 활용이 가능하다.
- GridFS는 16MB(BSON document 사이즈) 넘는 사이즈의 데이터를 저장하고 조회 하는 방법.
-
한개의 파일로 저장하는 대신에 부분이나 청크로 나누어 분리된 도큐먼트를 청크로 저장한다. 청크사이즈는 기본 256k로 제한되어 있다. 파일 청크와 메타데이터를 저장하는 두개의 컬렉션을 사용한다
- (참고) - 좋은 설명(영어)
- (참고) - mongodb gridfs (official doc)
- (참고) - MongoDB GridFS 개념잡기
Join 불가능
트랜젝션 처리 불가능
MongoDB에서는 데이터 갱신 및 입력이 바로 디스크에 쓰이지 않는다. (비동기식)
- 따라서 데이터가 유실될 가능성이 있음.
Auto-Sharding
- auto 라는 말은 왜 붙은걸까?
MongoDB Replica Set (Provides high availability)
- Master-Slave Repliaction
- 마스터는 읽기+쓰기, 슬레이브는 read
- Automatic Fail-over
References
- official mongodb-architecture
- introduction of Mongo
- Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Couchbase vs OrientDB vs Aerospike vs Neo4j vs Hypertable vs ElasticSearch vs Accumulo vs VoltDB vs Scalaris vs RethinkDB comparison
- 조영규블로그- MongoDB(몽고 디비) 특징 공부하기 / 몽고 DB란 무엇인가
- WHAT ARE THE KEY FEATURES OF MONGODB?
- What are the features of mongodb?(Quora)
- WiredTiger Internal
- cassandra-vs-mongodb